












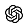


Kubernetes · Pod & Container Logs · K8s API Events · AI SDLC
Kubernetes Log Analysis —
Distill Your Pod and Event Signal.
Watch it, then run it on your stack
Pick where you already work:
LOG SEVERITY
LOGS
IMPACTED RESOURCES
SUMMARY
Run it on your cluster:
Run it in one terminal:
Run it in your editor:
Nothing to rip out · Works with your existing stack
43%
OF AI-GENERATED CODE FAILS IN PROD WITHOUT MANUAL DEBUGGING (LIGHTRUN 2026)
2
LOG SURFACES TO CORRELATE: POD LOGS AND K8S API EVENTS
90%+
OF RAW LOGS COLLAPSE INTO CLUSTERED SIGNAL
OTLP
NATIVE INGESTION ON DSTL8 AND GONZO
2 min
FROM brew install Dstl8 TO STREAMING CLUSTER LOGS
FIVE FAILURE MODES
Five Ways Kubernetes Logs Break the Debug Loop.
Kubernetes amplifies everything about logs. Replicas multiply sources, sidecars multiply streams per pod, auto-instrumentation multiplies volume per stream. Your existing stack stores all of it, faithfully. These are the patterns that break when the storage and search model has to double as a debugging tool.
01
The K8s haystack scales with every replica
Auto-instrumentation is the point. Every HTTP call, DB query, and framework callback becomes a log event. Multiply by replicas, containers per pod, and sidecars per container, and a ten-service cluster produces tens of millions of log lines a day. Your backend ingests all of it. None of it tells you which line is the incident.
10 services × 5 replicas × 3 containers (app + envoy + otel)
= 150 log streams
× auto-instrumentation + DEBUG churn
= 40M+ log lines/day
# search “error” → 60,000 results
# actual incidents → 2
02
kubectl and dashboards don’t aggregate the way you need to debug
kubectl logs is tactical. Great for inspecting one pod right now. Fails at every multi-pod, multi-container, cross-namespace scenario.
kubectl logs -f deployment/checkout
→ “maximum allowed concurrency is 5”
kubectl logs checkout-abc
→ “container name must be specified: [app, envoy, log-shipper]”
kubectl logs across namespaces
→ one kubectl command per namespace, no aggregation
pod crashed, need pre-crash logs
→ kubectl logs –previous, pray kubelet retained it
03
“What broke” without “why”
Your centralized logging backend — Loki, Datadog, Splunk, Elastic, CloudWatch — is designed for search and retention. When on-call fires, you get “pod restarted” or “error rate spiked” and still have to assemble the story by hand.
# r/sre, 45 upvotes
“You get alerts like ‘CPU spike’ or ‘pod restart.’
Cool, something broke.
But you still have no idea why.”
# r/devops, on-call thread
“someone digging thru logs,
someone else flipping between grafana dashboards,
another person poking at traces.
feels busy but not always productive.”
04
App logs and K8s events are two separate debug surfaces
CrashLoopBackOff, OOMKilled, ImagePullBackOff, FailedScheduling. The cause lives in K8s API events. The upstream effects live in application logs of other services. Debugging means jumping between two surfaces and correlating by hand.
# bad image deploy on checkout-service
K8s API events → ImagePullBackOff on checkout-7d8f9b
application logs → 500s from load-generator, checkout-proxy, timeouts in cart-service
# two surfaces, one incident, manual correlation
05
“Shotgun-into-LLM” AI tools burn tokens and miss the signal
Some AI observability tools pipe raw log streams directly into a language model and let it guess. The result is vague, expensive, and not grounded.
raw logs → LLM → “something in your cluster broke”
40,000 lines/hr → tokens → $$$$
no baseline, every error → looks anomalous
no citation, every answer → could be hallucinated
# on-call tax goes up, signal quality stays flat
WHY THIS MATTERS
Your existing K8s logging stack solved storage and search. It was not designed for the debug loop the AI SDLC demands, and shotgunning the same raw logs into an LLM makes the problem more expensive, not more solvable. The piece that’s missing is distillation and enrichment happening before any AI layer touches the data.
The solution
How K8s Teams Turn Log Volume Into Signal.
Dstl8 is a three-layer pipeline that sits alongside your existing K8s logging backend. Raw logs never go to the AI layer. By the time Möbius reads anything, the stream has been clustered, baselined, enriched with K8s context, and correlated across surfaces.
1. DISTILL → Pattern clusters, severity baselines per service,
sentiment scoring, anomaly detection, dedup
2. ENRICH → OTLP resource attributes preserved, K8s API event
correlation, pattern fingerprinting for cross-service
linkage, severity normalization
3. EXPLAIN → Möbius reads the distilled signal, ranks incidents,
cites the specific pattern, event, or counter behind
every claim
Distillation runs first, always
Repeated patterns collapse into clustered signals with counts. DEBUG storms, retry loops, and sidecar chatter become single rows, not tens of thousands of events. Per-service severity baselines mean checkout-api’s normal isn’t confused with auth-service’s normal. 90%+ of raw log volume compresses into the signal layer Möbius reads.
Enrichment joins the two K8s log surfaces
Application logs from pod stdout and K8s API events (ImagePullBackOff, OOMKilled, FailedScheduling, etc.) flow through the same pipeline. Dstl8 correlates them by pod, namespace, deployment, and cluster. The bad-image-deploy scenario that used to span two tabs becomes one incident.
Möbius reads distilled signal, not raw logs
The AI layer operates on clustered patterns, severity deltas, and correlated events — a compact, structured view. Every incident narrative cites the specific pattern, event, or counter it was built from. No “maybe Kubernetes?” RCAs. Token spend is bounded by incident volume, not log volume.
OTel-native, not OTel-dependent
Dstl8 and Gonzo both speak OTLP natively over gRPC and HTTP. Already running the OpenTelemetry Collector with filelogs and k8sobjects receivers? Add Dstl8 as one more exporter. Prefer terminal-native? Gonzo works as an OTLP receiver too, or talks to your cluster directly through kubeconfig. Not running OTel at all? Dstl8’s direct collection path covers pod logs and K8s events without a collector prerequisite. Your existing logging backend stays untouched in every case.
Query incidents from Claude Code, Cursor, or your terminal
Dstl8 exposes an MCP server. Ask “what’s new in the checkout-service since the last rollout” or “why is the api-gateway pod CrashLoopBackOff-ing” from inside your editor. Answers are grounded in the distilled signal with cited evidence.
What you get
How K8s Teams Ship AI-Generated Code With Confidence.
MÖBIUS
Möbius reads distilled signal. Not raw logs.
The shortcut approach — shotgunning every log line to an LLM — burns tokens and produces vague “maybe Kubernetes?” RCAs. Dstl8 runs pattern clustering, sentiment, severity baselining, anomaly detection, and K8s event correlation first. Möbius reads that distilled signal and generates incident narratives only for ranked anomalies, with every claim linked back to the specific pattern, event, or counter that produced it.
COMPLEMENT
Keep your backend. Dstl8 speaks OTLP natively.
2 ways to get logs in
Dstl8 doesn’t replace Loki, Datadog, Splunk, Elastic, or CloudWatch. It sits alongside and adds the distillation and AI layer your current stack was never designed to provide. Native OTLP ingestion means if you already run the OpenTelemetry Collector, Dstl8 is just one more exporter. If you don’t run OTel, Dstl8 collects pod logs and K8s events directly. No re-instrumentation, no rip-and-replace.
TWO-SURFACE
Dstl8 correlates pod logs with K8s API events.
2 log surfaces, one incident
CrashLoopBackOff, ImagePullBackOff, OOMKilled, and FailedScheduling live in K8s API events. Their upstream impact lives in your application logs. Dstl8 ingests both surfaces — via the OTel Collector’s filelogs and k8sobjects receivers, or direct collection if you’re not running OTel — and correlates them by pod, deployment, namespace, and cluster. One incident view, not two tabs.
AI SDLC
Built for the deploy cadence AI tools create.
Claude Code, Cursor, and Copilot ship more code, faster, than your K8s observability stack was designed for. Dstl8 tracks pattern emergence against each service’s baseline, so when a new rollout introduces a new failure mode, the pattern change shows up immediately — not when someone notices the dashboard has a new shape.
SCALE
90%+ of raw logs collapse into clustered signal.
90%+raw logs reduced to signal
Pattern clustering, deduplication, and severity baselining typically compress a noisy K8s log stream into a small fraction of the original volume. That’s what Möbius reads — signal, not a firehose — which is why token spend stays bounded and incident narratives stay grounded. Your existing backend still receives whatever you send it today; Dstl8 operates on the signal layer alongside.
Get Started
Native K8s. Native OTLP. Aggregates across pods and namespaces.
2 min to streaming cluster logs
Gonzo talks to your cluster through your existing kubeconfig — same context kubectl uses — and aggregates pod logs across namespaces, deployments, and label selectors in your terminal. It’s also a native OTLP receiver over gRPC and HTTP, so if you run the OpenTelemetry Collector, Gonzo plugs into it as an exporter destination. Pattern detection, severity heatmaps, filters, and on-demand AI summarization throughout. Bring in Dstl8 when you want K8s API event correlation, continuous coverage, and cross-cluster pattern detection.
Your options
Kubernetes Log Analysis and RCA : How Teams Actually Solve This.
Capability
Store and search pod logs
Long-term retention and compliance
Native OTLP ingestion
Cross-pod / cross-namespace log aggregation
Pod log + K8s event correlation
Per-service severity and pattern baselines
Distillation + enrichment before AI analysis
Grounded incident narratives with log citations
Bounded LLM token cost regardless of log volume
Query incidents from Claude Code / Cursor / terminal
YOUR K8S LOGGING STACK
“AI SRE” BLACK BOXES
ControlTheory
Common questions
Kubernetes Log Analysis — Questions from SRE and Platform Teams.
Get started
Install & Configure Dstl8 in Under 2 Minutes.
Try the Dstl8 CLI and TUI for continuous runtime feedback. Install it, add sources, connect the MCP server into Claude Code, and more.
brew install control-theory/dstl8/dstl8
dstl8 signupcurl -fsSL https://install.dstl8.ai/script/dstl8-cli | shnpx dstl8nix run github:control-theory/dstl8Download from https://github.com/control-theory/dstl8/releasesQuick Start
# 1. Install the CLI
brew install control-theory/dstl8/dstl8
# 2. Create a Dstl8 account (or `dstl8 login` if you already have one)
dstl8 signup
# 3. Add a source so logs flow in
dstl8 sources add vercel
# 4. Connect your AI agent, auto-detects MCP-compatible clients on your machine and configures them
dstl8 install --all
dstl8 install claude-codeAdd Sources
# Add Sources
dstl8 sources add kubernetes
dstl8 sources add cloudwatch
dstl8 sources add vercel
dstl8 sources add supabase
dstl8 sources add otlp
dstl8 sources add githubStart Here
See what’s actually happening.
Connect your deployment chain. Surface emergent patterns. Get root cause analysis with fix recommendations — right in your editor.
↻ Intelligence that compounds — every runtime signal makes the next one sharper.
Dstl8 — Supabase runtime analysis


Open Source
Not ready for Dstl8? Start with Gonzo.
Free, open source log analysis TUI. Real-time charts, pattern detection, AI-powered insights — right in your terminal. No account, no config.
brew install gonzo
Keep Your K8s Logging Stack. Add the Signal Layer.
Point Gonzo at your cluster with --k8s-enabled and have streaming pod logs in 2 minutes, or plug into your existing OTel Collector with native OTLP. Then add Dstl8 when you want continuous distillation, K8s API event correlation, and Möbius answering questions grounded in cited log evidence. Nothing to rip out, no shotgun-LLM tax.
Related pages
More for K8s Teams Shipping With AI Tools.
Your K8s Stack Stores the Logs.
We Distill the Signal.
Free, open source, terminal-native. Point Gonzo at your cluster with one flag and start aggregating pod logs across every namespace in 2 minutes. Upgrade to Dstl8 when it’s time for K8s event correlation and Möbius-grounded RCAs.