














AI SDLC · Production Feedback Loop
Your AI Agents Write Code. Dstl8 Teaches Them What Actually Breaks.
AI has collapsed the software development lifecycle. Code gets written faster than teams can validate it. Dstl8 closes the agentic AI feedback loop — feeding production patterns, incident history, and real failure context to your AI agents before they write the first line.
Zero
Production Context in Most AI Coding Workflows
10x
Code Shipped Per Engineer, Same Validation Tools
70%
of Incidents Repeat Known Patterns
2 min
Time to First Distilled Insight
Continuous
Agentic AI Feedback Loop
Six failure modes
Six Ways the AI SDLC Breaks Without Production Context.
The software development lifecycle has changed. AI agents now write, review, and refactor code at a pace the old SDLC model was never designed to validate. Speed without grounding produces six predictable failure modes — and they compound as AI adoption scales across the team.
01
AI agents write code with zero awareness of how it actually runs.
Your AI agent has read your codebase. It has not read your incidents. It does not know which endpoint flaked last Tuesday, which migration silently corrupted data for a subset of tenants, or which feature flag is currently hiding a race condition. It writes what looks right against the code it can see — not against the system as it actually runs.
// AI agent generates
fetch(‘/api/v2/billing/charge’)
.then(r => r.json())
.then(data => updateInvoice(data))
// Production reality — last 30 days
ERROR /api/v2/billing/charge · 503 spikes
WARN intermittent empty response body
INFO v2 deprecated · migration blocked
(none of this surfaced in the codebase)
02
Regressions ship silently between deploy and the first user complaint.
In the classic SDLC model, QA sat between “developer thinks it’s done” and “user finds the bug.” That gate has effectively collapsed. AI-generated PRs merge faster than humans can review them, and there is no automated step that compares post-deploy behavior against the pre-deploy baseline. Regressions arrive in production wearing the uniform of a successful deploy.
13:42 deploy succeeded · all green
13:44 background job queue depth +340% // no alert, within soft threshold
13:51 checkout conversion –12% // not tracked as a signal
14:17 first support ticket // ← detection starts here
14:46 rollback · 64 minutes degraded
03
Incident knowledge lives in three senior engineers’ heads.
The person who debugged the last cascading failure remembers the shape of it. The fix lives in a Slack thread, a closed PR description, and their memory. When they go on leave — or leave the company — that knowledge goes with them. AI agents, which would otherwise be perfect recipients of that context, have no interface to it.
# The institutional memory graph
Jane → knows the 2024 queue-depth cascade root cause
Miguel → knows why /auth retries three times in staging
Priya → knows which RLS policy breaks for free-tier users
# What the AI agent sees
(nothing)
04
New engineers spend months absorbing context that already exists in the logs.
Onboarding used to be about the codebase. Now it is mostly about learning what the codebase does not tell you — the weird tenant, the legacy webhook, the quiet infrastructure limit. That context exists in the log stream and in the incident history. It just isn’t structured for a human — or an AI agent — to learn from.
Week 1-4: read the codebase
Week 5-8: break something small
Week 9-12: finally hear the story about the 2023 outage
Week 13+: start to pattern-match incidents against history
← value creation starts here
05
Test suites reflect what developers guessed might break — not what broke.
Test coverage is a proxy for reliability, not a measure of it. Most suites are written against developer intuition about edge cases, assembled from the shapes of bugs the team remembers. Real production failures — weird payloads, unexpected traffic patterns, infrastructure behavior under load — rarely map cleanly onto unit tests. AI agents, asked to generate tests, reach for the same intuition the humans used.
// What the test suite covers
describe(‘charge’, () => {
it(‘handles a valid charge’, …)
it(‘rejects an invalid amount’, …)
})
// What actually broke in production
Stripe webhook retries with a new event ID, same idempotency key
Customer with 47 subscriptions triggers query timeout
Region failover returns 202 where code expects 200
06
Logging blind spots only reveal themselves after the outage they caused.
Instrumentation decisions get made at writing time, when the developer is thinking about the happy path. The silent failure path, the ambiguous error state, the payload that should have been captured — none of it gets logged. You discover the gap during the post-mortem, when the evidence you needed doesn’t exist. AI agents produce this pattern at scale: plenty of logs, in the wrong places.
// What got logged
[INFO] request received
[INFO] validation passed
[INFO] response 200
// What broke
(payment provider returned a new error code in the middle of the flow)
(no log captured it · no alert fired · user saw a blank screen)
The point of view
The SDLC isn’t dead — it’s decoupled. Writing code is no longer the bottleneck. Validating code against production reality is. Every AI SDLC framework in the market optimizes the left side of the lifecycle: planning, scaffolding, code generation. The right side — the feedback loop from production back into the next line of code — is where the work now lives. An agentic AI feedback loop without production signal is just a faster way to ship the same class of bug.
The solution
An AI SDLC Framework Grounded in What Actually Happened.
Dstl8 is the production signal layer for AI-native development. It distills your logs, incidents, and infrastructure events into structured context, then delivers that context to your AI agents and your humans through the same interface. Gonzo, its open source companion, gives you raw log visibility during local development so problems surface before they ship.
AI agents start with production context, not a blank slate.
Before the first line of generated code, your AI agent knows what’s on fire, what flaked last week, and which fix actually resolved the incident three sprints ago. Dstl8 exposes active incidents, historical patterns, and resolution context through MCP. The agent reads it the same way it reads your repo.
Every deploy is automatically compared against baseline.
Post-deploy log patterns get distilled against the previous baseline in staging. New error shapes, unfamiliar log signatures, silent failure modes that weren’t there yesterday — all surface before the rollout continues. Gonzo handles the same thing in your local development terminal: raw signal, no config, running inside Cursor or wherever you work.
Incident history is treated as first-class infrastructure.
Every incident, evidence trail, and resolution is captured and scored. AI agents correlate that history with commits and fixes via source control MCP, so the solutions they generate are grounded in what actually worked — not in what looked plausible on Stack Overflow.
Every engineer, and every AI agent, starts with the team’s full context.
Shared workspaces mean historical pattern scoring is available to everyone on day one. A new hire asking “why does this service behave like this” gets the same answer an AI agent asking the same question gets — derived from the actual log stream, the actual incident history, and the actual commits that resolved the last one.
Test cases get generated from real production failures.
Dstl8 surfaces the payloads, traffic patterns, and infrastructure conditions behind real incidents. AI agents pick those up through MCP and generate concrete test cases from them. Your suite stops reflecting developer intuition and starts reflecting what actually happened.
Instrumentation gets better every time you ask why something wasn’t caught.
When a failure slips past distillation, that’s the moment the gap becomes visible. Ask Dstl8 why a pattern wasn’t flagged earlier and the answer surfaces the real cause — missing context on a failure path, a silent error with no log entry, noise drowning out the signal. AI agents pick up that answer, cross-reference it with the code via source control MCP, and recommend precise logging improvements. It’s the only feedback loop that improves the quality of the raw signal itself.
What you get
A Production Feedback Loop for AI Agents and the Humans Working With Them.
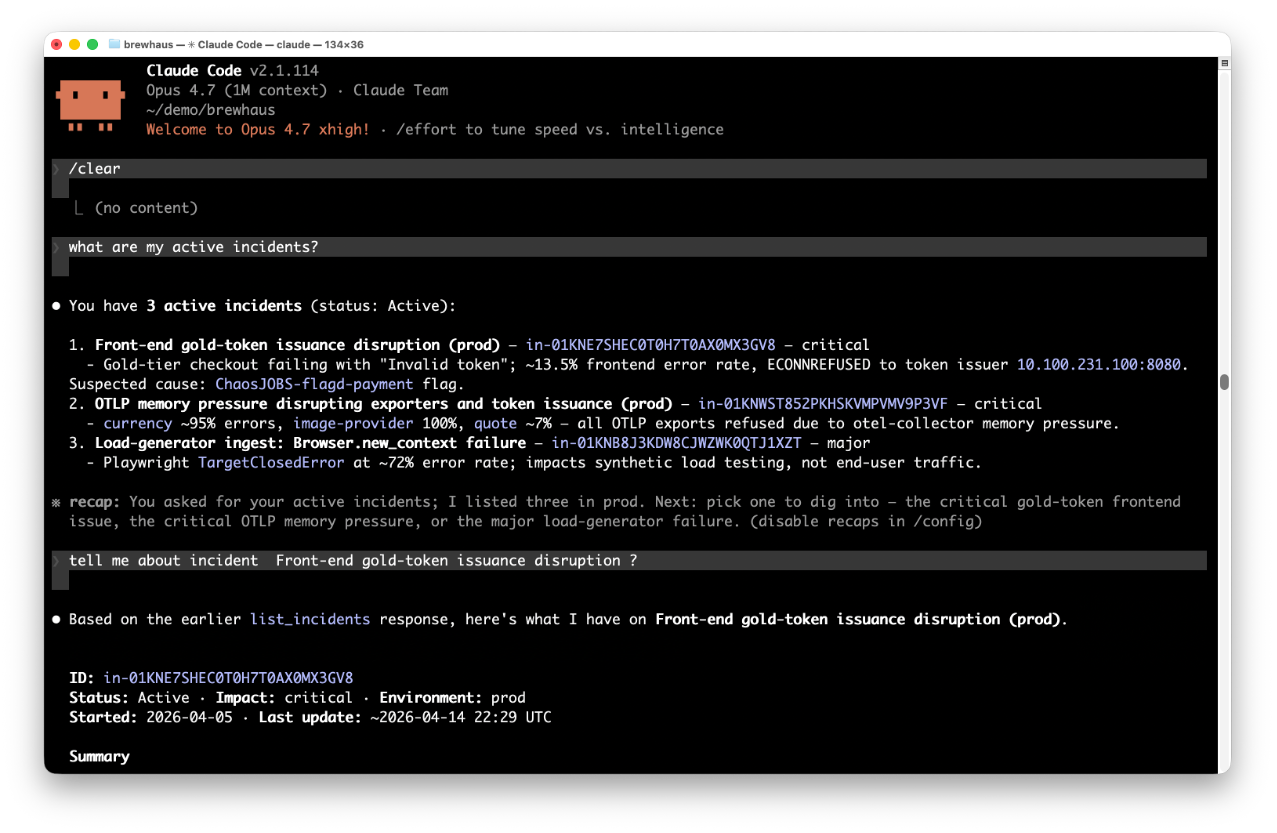
Active Incidents
See what’s breaking before an AI agent generates code into the same failure.
Every active incident, ranked by severity, with timestamps and source. Your AI agent reads the same list through MCP. Planning a refactor against a service currently degrading becomes a choice, not an accident.
AI in SDLC at Scale
The feedback loop that keeps up with AI code generation.
10x code volume, same validation tools
Code generation scaled. Testing, review, and incident correlation didn’t. Dstl8 is built for the gap that opened when writing stopped being the bottleneck.
Incident Detail
A diagnosis, evidence, and an action list — consumable by humans and AI.
Description of what’s happening, evidence with specific data points, and a numbered action list. Shared workspaces compound that value over time — every past diagnosis stays available to every future AI agent prompt and every new team member. The system gets better the longer it runs.
Mobius
Ask it anything about your system — in natural language.
Mobius is Dstl8’s AI analysis engine. It distills your log streams continuously, detects anomalous behavior, and produces diagnoses grounded in your actual data.
Get Started
Start with Gonzo — free, open source, 2 minutes.
2K+ GitHub stars
Gonzo is the terminal-native log analysis tool that feeds the bigger picture. No config, no cloud account. Run it alongside your AI coding tool and you’re reading real production signal before the next deploy.
AI SDLC tooling landscape
AI SDLC Tools Compared: Where the Feedback Loop Actually Closes.
Capability
Production context fed to AI agents
Incident history as structured memory
Post-deploy regression detection vs. baseline
Test case generation from real failures
Instrumentation gap detection
Shared context for new team members
Time to first insight
Traditional SDLC Tools
AI Coding Tools Alone
Generic Error Tracking
ControlTheory
Common questions
AI in SDLC — Questions from Engineering Leaders.
Get started
Start With Gonzo. Add Dstl8 When the Team Needs It.
Gonzo is the open source terminal UI that feeds the bigger feedback loop. No account, no agent to install in production, no configuration. Run it in your AI coding tool’s integrated terminal and you’re reading signal in two minutes.
Install Gonzo
Gonzo tails your log streams, surfaces patterns by severity, and sends individual entries to an LLM for explanation — all from your terminal. It’s the fastest way to bring real production signal into your AI SDLC workflow.
brew install gonzo
go install github.com/control-theory/gonzo/cmd/gonzo@latest
# Download the latest release for your platform from the releases page: # github.com/control-theory/gonzo/releases
nix run github:control-theory/gonzo
git clone https://github.com/control-theory/gonzo.git cd gonzo make build
Usage Examples
# Tail multiple log files:
gonzo -f application.log -f error.log -f debug.log
# Deploy and watch logs on Vercel:
vercel –prod –follow –output json | gonzo
# Stream from an existing deployment:
vercel logs –follow –output json | gonzo
# Pipe any source:
kubectl logs -f deployment/api | gonzo
railway logs | gonzo
Close the loop between your AI agents and your production system.
Free account. Gonzo running locally in two minutes. Early access to Dstl8 and the MCP integration that teaches your AI agents what actually breaks.
AI Writes the Code. Dstl8 Grounds It in Production Reality.
The agentic AI feedback loop isn’t complete until real production signal reaches the next prompt. Start with Gonzo — open source, terminal-native, running in two minutes.