














Use Case · Make AI-Generated Code Better Over Time
Make AI-Generated Code Better Over Time. Not Just Faster This Week.
Your team ships 10x more code with AI tools. Without a runtime feedback loop, you also ship 10x the ways it can fail. Dstl8 reads every runtime failure, distills the pattern, and feeds it back into how the next prompt gets written, the next test gets scoped, and the next priority gets set. Every incident becomes input to your software development lifecycle (SDLC). The AI gets better because the signal finally got there.
brew install control-theory/dstl8/dstl8
5 Feedback Loops
fix · test · generate · prioritize · release
Knowledge graph
Persists across sessions
Cited
Evidence behind every pattern
Compounding
Every incident becomes input to the next prompt
What changed
AI made the first 10,000 lines cheap. The next 100,000 will cost you.
The first six months of AI-generated code is exciting. Velocity is obvious. Ship counts are up. The code base is getting bigger, the team’s mental model of it is getting smaller, and the AI’s mental model of production is nonexistent. Something has to feed runtime back into how code gets generated, or every new feature is a fresh chance to ship a variation of a failure class you already paid for.
The AI SDLC does not self-improve. The runtime has to get back into the generation.
TLDR
Velocity without feedback is compounding risk. Dstl8 is the input the AI SDLC has been missing.
How Dstl8 works
Five feedback loops Dstl8 closes in your AI SDLC.
The AI SDLC does not self-improve by default. Dstl8 is the runtime input that closes each of these loops. Every incident becomes structured context the AI SDLC can act on: fixing, testing, generating, prioritizing, and releasing with production grounded as the baseline.
01
Fix loop — diagnosis feeds the next prompt.
When an incident gets resolved, Dstl8’s Möbius agent writes the root cause, the cited evidence, and the fix into the knowledge graph. The next Claude Code or Cursor session on that code path pulls the context in through MCP or the Skill. The next fix is informed by what actually happened, not by what the test file says.
# what the fix loop produces
root cause · cited evidence · knowledge graph entry
# what the next session inherits
prior diagnoses · class patterns · suggested guards
02
Test loop — real failures become real test cases.
Dstl8’s Möbius agent names the runtime pattern: the field shape that broke, the event type that triggered it, the edge case your tests missed. That diagnosis becomes structured input for writing the test that would have caught it. Test coverage compounds from actual production experience, not imagined edge cases.
# what möbius names
pattern · trigger · edge case · affected surface
# what the next test covers
the failure that actually happened · not the one you imagined
03
Generate loop — the AI writes code that knows production exists.
Runtime context is available to the AI coding tool at generation time. The MCP surface exposes the knowledge graph. The Skill teaches the agent when and how to query it. The agent writes a guard for a failure class because the knowledge graph surfaced the class, not because a test flagged it. Code quality improves as a function of runtime experience, not prompt engineering.
04
Prioritize loop — impact drives the backlog, not noise.
Dstl8’s Möbius agent ranks incidents by runtime impact: which failure classes affect the most users, ship the most errors, touch the most code paths. Your team works on what runtime says matters most, not on what the loudest ticket reporter escalates. The backlog reflects production, not Slack.
05
Release loop — deploy confidence from runtime, not staging.
Every deploy ships into a runtime Dstl8 is already reading. When behavior shifts after a release, its Möbius agent correlates the deploy event (surfaced through GitHub integration) against the new runtime pattern and names the change. The next release goes out with the prior one’s runtime signal already known, so confidence is earned from production, not inferred from a green test suite.
TLDR
Five loops, one input. Runtime is the thing the AI SDLC was missing.
Real world use case
Same class of bug. Three encounters. Three different outcomes.
An example failure class every team running a vibe + AWS stack has hit: payload-shape assumptions that break when upstream providers add or reshape fields. Here is what that class looks like across three encounters over a quarter, when runtime signal is feeding back into the AI SDLC.
Encounter 1 — Month 1.
Stripe adds a metadata field to a subscription webhook payload. The AI-generated handler, shipped last sprint, did not account for the new field. Paid customers start losing entitlements. Dstl8’s Möbius agent detects the pattern in minutes, names the payload-shape cause with cited evidence, and suggests the fix. The resolution and the failure class both land in the knowledge graph. Fifteen minutes from detection to committed fix.
Encounter 2 — Month 2.
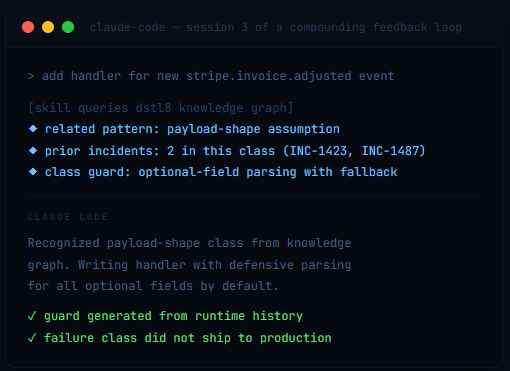
A different engineer on the team ships a new invoice webhook handler. The field in question is optional, and the Claude Code session generates code that assumes it is always present. Before deploy, the Dstl8 Skill queries the knowledge graph for related patterns. The payload-shape class from Encounter 1 surfaces. The agent writes the optional-field guard into the handler before it ships. The failure never reaches production.
Encounter 3 — Month 3. Stripe introduces a new event type. The team adds support via Cursor. Dstl8’s MCP surface is already in the agent’s context. The agent reviews the knowledge graph’s payload-shape class entry, recognizes the new event type as a potential variation of the same class, and generates the handler with defensive parsing as the default. The failure class is no longer a bug to rediscover. It is a guard pattern the AI reaches for automatically.

Failure class: payload-shape assumption · Runtime surface: Stripe + Vercel + Supabase
Compounding shape: 15 minutes → 0 minutes → 0 minutes, with class-level prevention by month 3
TLDR
The bug that took 15 minutes in month 1 stopped shipping by month 3. The class got solved once; the AI carried it.
Why Dstl8?
Compounding is the product. Every incident is input.
Knowledge Graph
Findings compound across sessions, engineers, and deploys.
When an incident gets resolved, the root cause, the evidence, and the fix land in the knowledge graph. A Claude Code session next week on a similar failure class pulls the known answer through MCP or the Skill, not a cold-start diagnosis. Engineers rotate; pagers rotate; context does not get re-paid for.
Prompt Context
The AI finally knows what production looks like.
Runtime is available to the agent at generation time. Guards get written because the knowledge graph surfaced the class, not because a test flagged the shape.
Test Enrichment
Next test is a real failure, not a guess.
Möbius names the pattern. The next test covers the failure that actually happened. Test coverage compounds from production, not from imagination.
Prioritize
Backlog reflects runtime, not Slack.
Möbius ranks failure classes by how many users they hit, how many requests they ship, how many code paths they touch. Your team works on what runtime says matters most. The highest-impact failure class gets the first fix, and the knowledge graph makes sure the fix compounds.
Learn more
Related reading for the SDLC you are compounding into.
This use case sits at the top of the AI SDLC stack. These pages go deeper on the agents, tools, and failure classes that make compounding feedback loops worth closing.
Common questions
What teams ask before adopting this.
Get started
Install & Configure Dstl8 in Under 2 Minutes.
Try the Dstl8 CLI and TUI for continuous runtime feedback. Install it, add sources, connect the MCP server into Claude Code, and more.
brew install control-theory/dstl8/dstl8
dstl8 signupcurl -fsSL https://install.dstl8.ai/script/dstl8-cli | shnpx dstl8nix run github:control-theory/dstl8Download from https://github.com/control-theory/dstl8/releasesQuick Start
# 1. Install the CLI
brew install control-theory/dstl8/dstl8
# 2. Create a Dstl8 account (or `dstl8 login` if you already have one)
dstl8 signup
# 3. Add a source so logs flow in
dstl8 sources add vercel
# 4. Connect your AI agent, auto-detects MCP-compatible clients on your machine and configures them
dstl8 install --all
dstl8 install claude-codeAdd Sources
# Add Sources
dstl8 sources add kubernetes
dstl8 sources add cloudwatch
dstl8 sources add vercel
dstl8 sources add supabase
dstl8 sources add otlp
dstl8 sources add githubStart Here
See what’s actually happening.
Connect your deployment chain. Surface emergent patterns. Get root cause analysis with fix recommendations — right in your editor.
↻ Intelligence that compounds — every runtime signal makes the next one sharper.
Dstl8 — Supabase runtime analysis


Open Source
Not ready for Dstl8? Start with Gonzo.
Free, open source log analysis TUI. Real-time charts, pattern detection, AI-powered insights — right in your terminal. No account, no config.
brew install gonzo
Start the Loop Now, Compound Later.
Free account. Connect your runtime sources, connect GitHub. Every incident Dstl8 resolves from here on becomes input to the next prompt, the next test, and the next priority call.
Velocity is table stakes. Compounding velocity is the product.
Dstl8 is the missing input to your AI SDLC. Connect it once, and every incident from here on makes the next one rarer.