
Observability has become a cornerstone of modern software operations—but let’s face it, it’s broken. Costs are spiraling, signal-to-noise ratios are off, and teams are stuck in a frustrating loop of over-instrumenting and then ripping it all out to save money. What if instead of just observing your systems, you could actually control them?
Controllability vs Observability
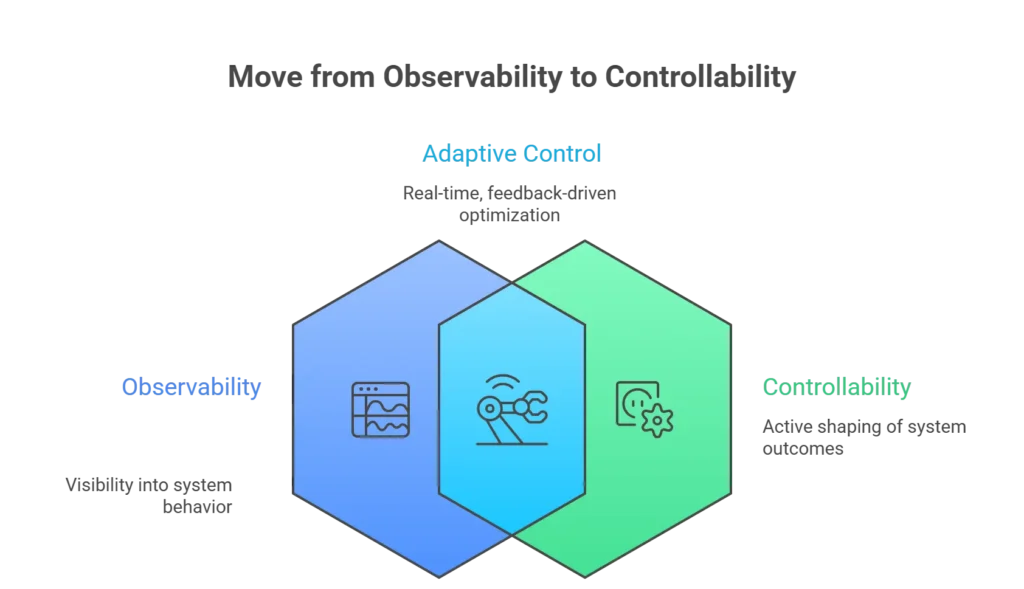
At ControlTheory, we believe it’s time to move beyond Observability to something more actionable: Controllability. Borrowed from the field of Control Theory, Controllability is about using feedback loops not just to watch your systems, but to actively shape and optimize their behavior. In this post, we’ll break down what Controllability really means, how it differs from traditional Observability, and the three pillars that make it work: Cost Control, Operational Control, and Adaptive Control.
What is Controllability?
Well, let’s start with was it isn’t. It isn’t continuing to send an ever increasing amount of telemetry data via 1 way “dumb pipes” to our existing observability vendors, who are happy to take it, and charge you for every byte ingested, stored or indexed. It isn’t a continuation of increasing MTTI and MTTR, which continue to go up, despite the aforementioned record levels of investment in our observability vendors. And it isn’t putting our development and engineering teams through a continuous cycle of knee jerk reactions, to remove instrumentation from our code to avoid cost overruns, only to add it back later because we need better insight – code changes which can have significant lead times, and absorb valuable cycles that could be used to move the business forward.
In short, current observability is broken, and we need to regain control of our observability data.
So what is Controllability really? How does it compare to Observability?
Well first up, it’s a longer word than observability (although both are long!) 🙂 Observability can be a mouthful to say, so it is sometimes abbreviated as “O11y” so Controllability in turn would be “C13y”!
On a more serious note, is an existing term that comes straight out of Control Theory – a field of engineering and mathematics that “deals with the control of dynamical systems in engineered processes and machines”, and “plays a crucial role in many control problems, such as stabilization of unstable systems by feedback, or optimal control.”. **** In fact, observability and controllability are “dual aspects of the same problem” to quote the 1st Wikipedia article linked earlier.
The Difference Between Observability and Controllability
We explored the differences between observability and controllability in a previous blog – in short control systems are relevant wherever we have feedback loops, and while observability deals with observing the state of the system, controllability is critical for altering the state of the system based on those observations, to drive to some desired outcome.
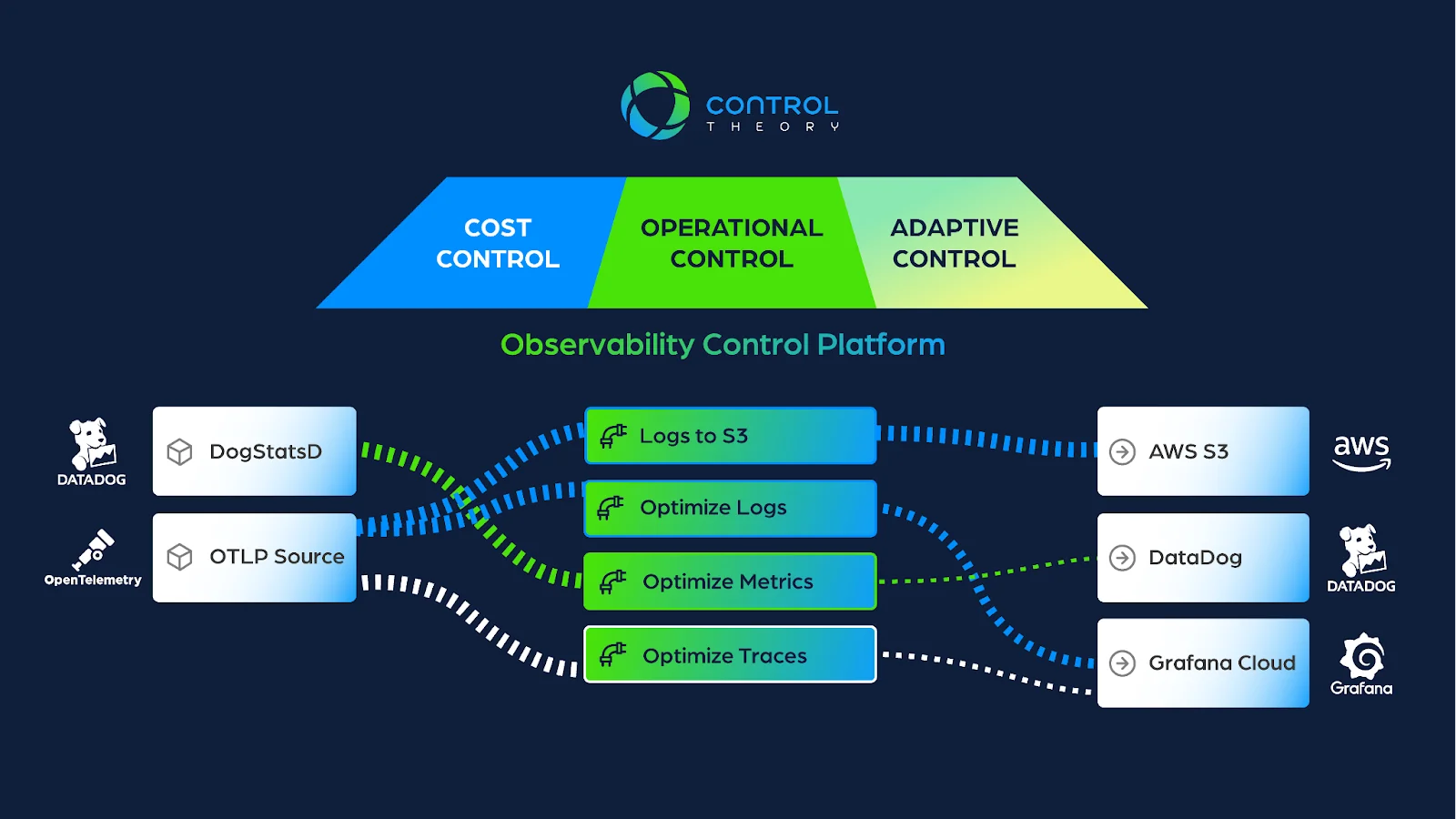
Here at ControlTheory, we view there as being 3 core outcomes we are trying to achieve – Cost Control, Operational Control and Adaptive Control.
Let’s dig into each of these a bit.
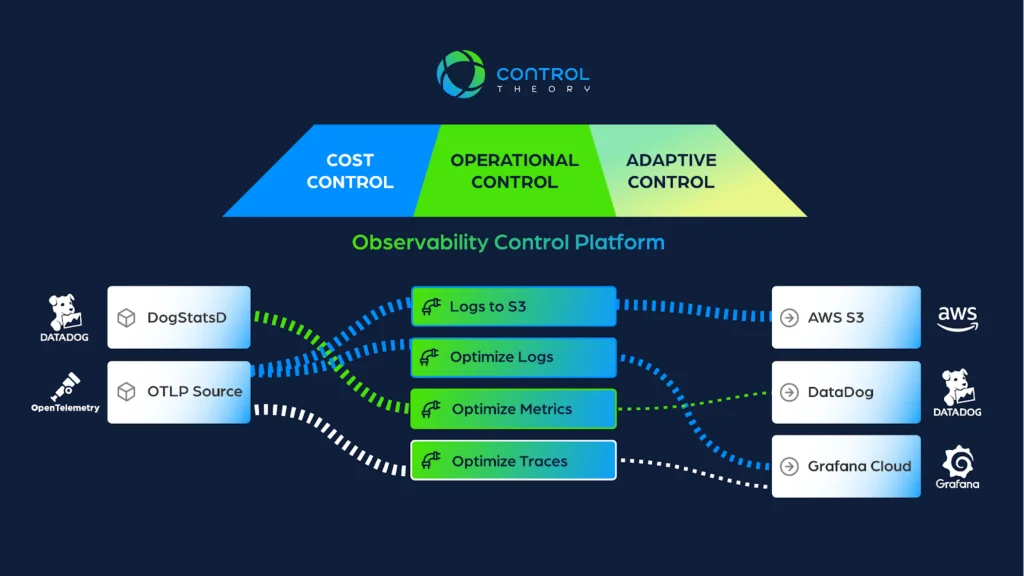
1st Controllability Outcome: Cost Control
Top of mind for just about everyone with an Observability vendor in place today is regaining control over their soaring observability costs. It’s not uncommon when we talk to customers to find that they uncover sudden or unexpected changes in their telemetry only when they look at their bill, at the end of the month, or even at the end of the quarter! Awkward conversations with the CFO ensue, often leading to some of the “knee jerk” reactions we talked about above.
MetaMetrics to the Rescue
There is a better way – using what we call “MetaMetrics” or the data about your observability data, we can get a proactive handle on underlying telemetry spikes or changes, and get attribution about where they’re coming from – what service, application or team is driving them – and were they caused by a recent code change?
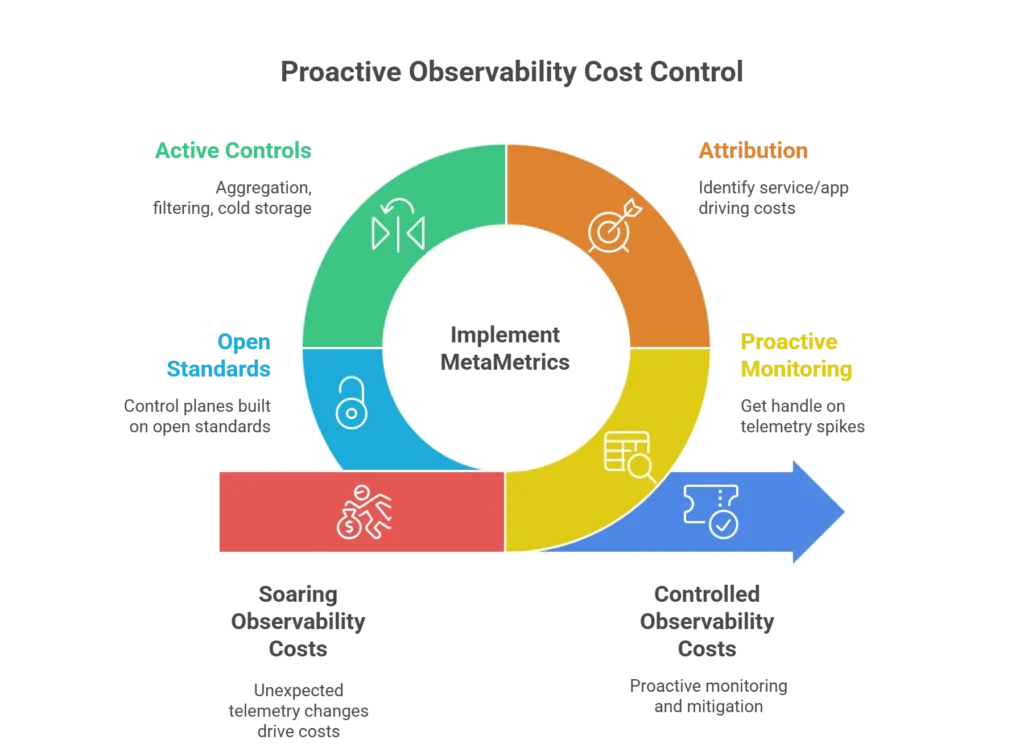
We can then leverage additional active controls to mitigate these costs such as aggregation and filtering to control high metric cardinality or log volumes, or by routing telemetry to low cost “cold storage” like AWS S3, where it can be rehydrated later if we need it.
OTel – Democratized Telemetry
Open standards also play a crucial role in controlling costs, and while OpenTelemetry is making headway in democratizing our telemetry data and avoiding lock in on data collection, we also need to ensure our control planes and systems we use to control our telemetry data are also “built on open”, lest we jump from one lock in situation to another.
2nd Outcome: Operational Control
While cost gets a lot of the headlines, it’s really a symptom of a larger issue of asking “why?” we’re observing in the 1st place. For many teams, the “why?” is around shortening the process of root cause analysis (RCA), reducing our MTTI and MTTR, and generating meaningful business KPIs, but doing so while ensuring security, privacy and compliance of our observability data.
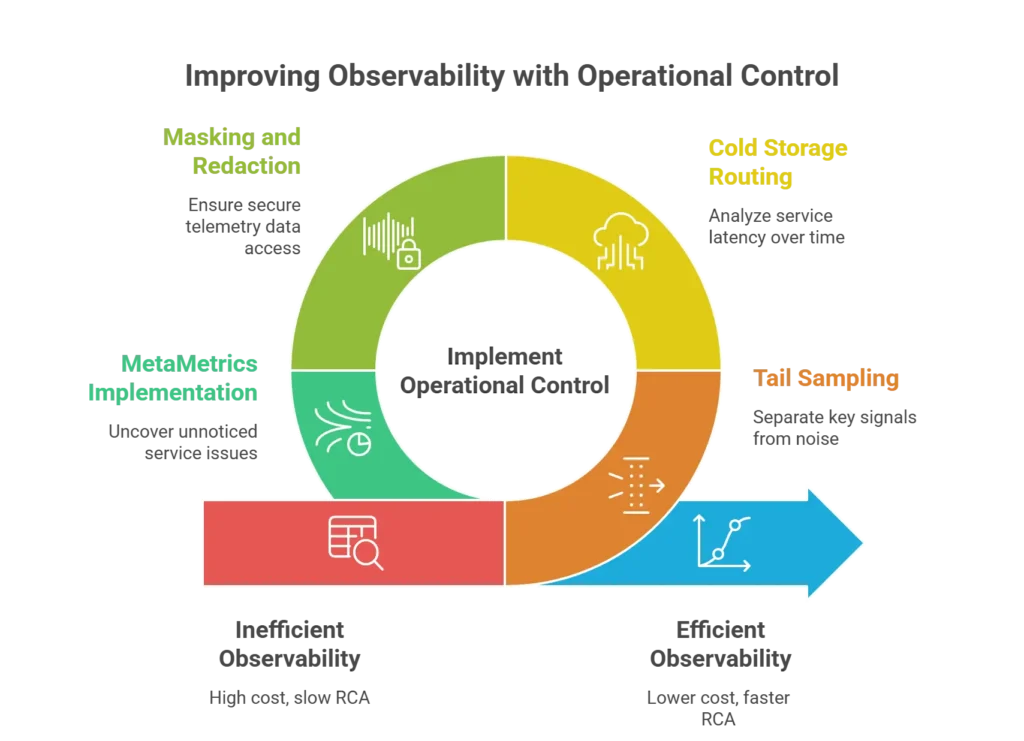
Controls like tail sampling allow us to separate the key signals from the noise (and cost), honing our engineering investigations into just those traces with high latency or errors, lowering MTTI and MTTR.
Evolved Set of Analytics for UX based on Telemetry & Metametric
Routing telemetry such as traces to cold storage like AWS S3 opens up new analytics possibilities, enabling us to analyze service to service latency or the customer experience over time (and releases), so we can answer the question “is our customer experience actually improving?” And this can all be done securely, through masking and redaction controls that ensure the right teams see the right telemetry data.
“MetaMetrics” are powerful here too, uncovering issues that many times go unnoticed, or as one customer put it “Individual ‘feature’ monitors didn’t trip, but the overall volume of data coming from the service raised eyebrows and allowed a faster response/remediation time.”
3rd Outcome: Adaptive Control
Finally, all of the controls above must be applied continuously, based on need, and driven through feedback loops. Due to the knee jerk reactions mentioned previously, development teams can become disincentivized to instrument key business applications and logic, for fear of cost overruns and reprisals. This is the opposite of what we want – we want our development teams to liberally instrument our applications for insights and better outcomes. Using adaptive controls, we can now enable our development teams, and control our telemetry at runtime.
Control Data Granularity Real-Time
Dialing up telemetry or increasing granularity when releasing a key new feature for example, or dialing up telemetry for a critical component during an incident. Real time visibility and feedback loops driven by MetaMetrics give you the real time cost impact of any changes.
And adaptive controls must meet you where you’re at, supporting the observability vendors and sources of data you already own, and do so in an open way as mentioned above.
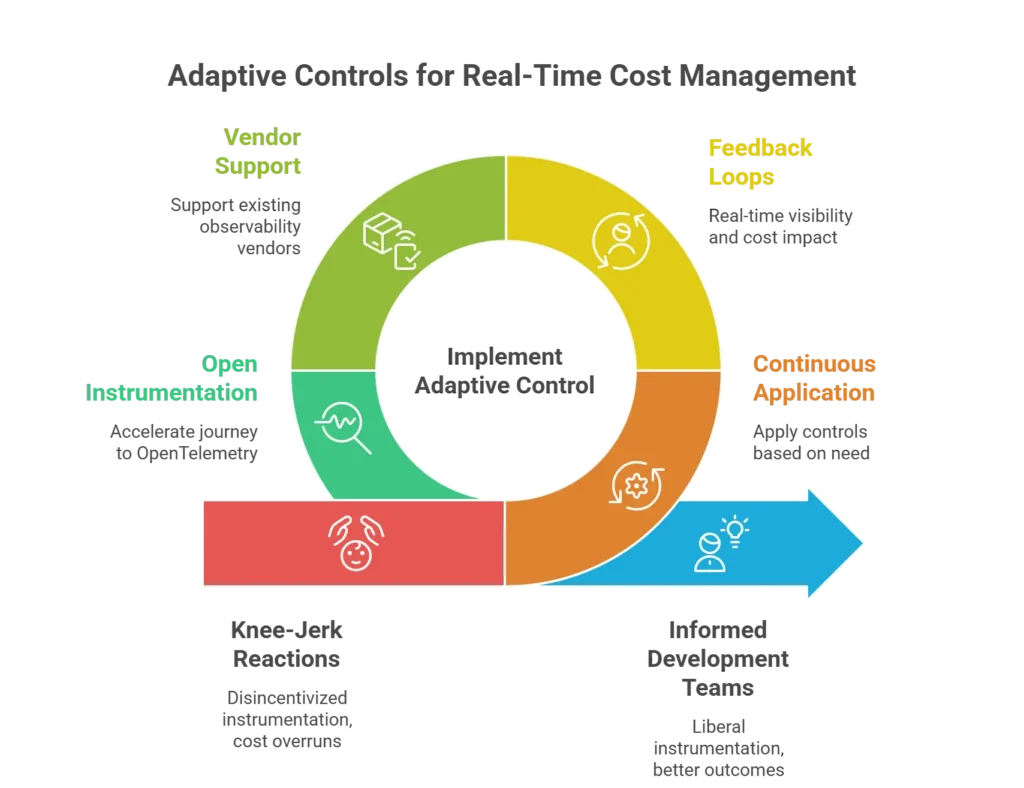
Furthermore, adaptive controls can aid with consolidations and migrations, even enabling you to accelerate the journey to OpenTelemetry instrumentation itself.
How can ControlTheory Help you to Apply Controllability in Practice?
Our platform supports active telemetry controls such as filtering, aggregation, routing, masking, redaction, and runtime adjustment.
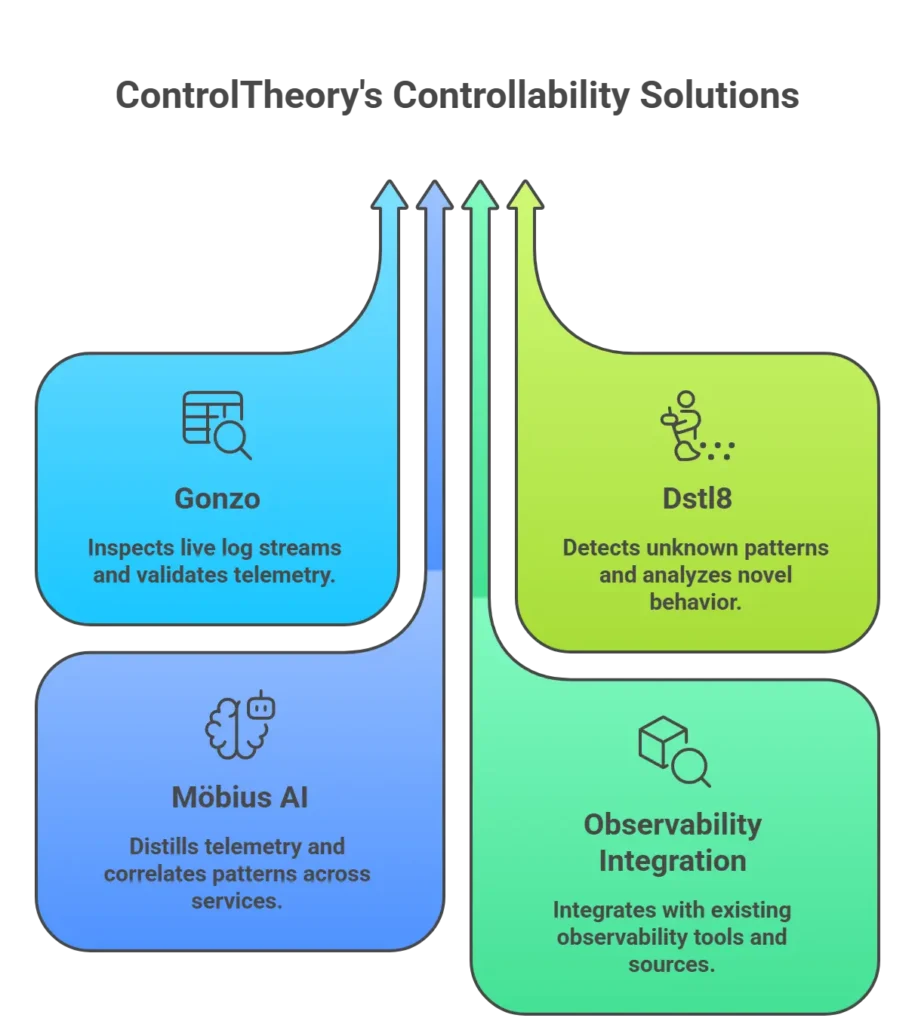
- With Gonzo, we give engineers a way to inspect live log streams, surface patterns, and validate emitted telemetry directly from the terminal.
- With Dstl8, we help teams detect unknown patterns, analyze novel behavior in dev, staging and production, and ground investigation in evidence rather than assumption.
- With Möbius AI, we add the continuous intelligence layer behind Dstl8 — distilling telemetry at the edge, correlating patterns across services and clusters, and helping explain incidents with evidence-backed context.
- We integrate with your existing observability stack rather than requiring replacement. Across ControlTheory, that means working with OpenTelemetry and more than 200 tools and sources — including AWS, Azure, Datadog, Elastic, Grafana Loki, Google services, New Relic, OpenSearch, and others — so teams can live-tail, analyze, distill, and optimize telemetry within the environments they already use.
Taken together, this allows us to move teams from passive observation to governed, feedback-driven software operations.
Summary
Controllability is the natural next step in the evolution of Observability—focused not just on seeing what’s happening, but taking action based on those insights. While Observability helps us understand the state of a system, Controllability enables us to shape that state in real time. At ControlTheory, this means:
- Cost Control: Regain visibility into where telemetry costs are coming from, and actively manage them using MetaMetrics, smart filtering, and open standards.
- Operational Control: Improve root cause analysis, compliance, and performance by filtering noise, elevating signal, and measuring what truly matters.
- Adaptive Control: Apply controls dynamically at runtime, empowering developers to instrument without fear and respond to changing conditions in real time.
Observability gave us visibility. Controllability gives us agency. It’s time to take back control.
FAQs – Controllability
Controllability is the capacity to move a system toward a desired state by applying suitable inputs. In classical control theory, it is treated as a core system property rather than a secondary tuning detail.
In our software-based framing, it extends observation into action: the objective is not only to measure system state, but to shape it through feedback.
Controllability and observability are paired concepts in control theory:
- Observability concerns whether outputs reveal the state.
- Controllability concerns whether inputs can drive the state.
Together, they determine whether a system can be both guided and understood.
Modern software operations often observe too much and control too little. This imbalance increases telemetry cost and weakens signal quality. It also lengthens the path from detection to remediation.
Controllability matters because software teams increasingly need to govern telemetry, not merely collect it.
In cloud applications, controllability means more than having tools to look at system behavior. It means being able to respond when the system deviates from its intended state, and to do so using evidence rather than guesswork. In distributed environments, that frequently extends to control over telemetry itself: its volume, granularity, routing, and runtime behavior.
Feedback loops connect measurement to intervention:
- In classical control theory, they help stabilize systems around a desired state.
- In software telemetry, they connect evidence to actions such as filtering, routing, sampling, and runtime adjustment.
- They also allow priorities to change during incidents, releases, or cost spikes.
Without feedback loops, telemetry remains a one-way transport mechanism.
Feedforward control acts on expected conditions before an error is fully expressed in system output. Unlike feedback control, it does not wait for deviation to become visible before responding.
- It is most effective when likely disturbances are known in advance.
- In controllability terms, feedforward expands the range of useful intervention by allowing earlier action.
- In software systems, this can correspond to proactive telemetry policy changes, workload-aware adjustments, or pre-emptive routing based on known risk conditions.
It does not replace feedback; in most real systems, the two work together.
AI coding tools compress the generation phase of development, but the feedback phase often remains unchanged. This creates an asymmetry: code reaches production faster than teams can verify its behavior. Fast feedback loops restore balance by returning evidence of runtime behavior at a cadence that matches the pace of change. Without that match, controllability exists in principle but not in practice.
When developers write every line, the codebase itself serves as a shared mental model for expected behavior. AI-generated code weakens that assumption – developers may ship logic they didn’t author and can’t fully predict. This shifts the control surface from the code to its runtime behavior: telemetry volume, failure patterns, dependency interactions, and drift from intended state all become things that need active governance, not just passive collection.
Table of Contents
Surface Unknown Unknowns Automatically
Catch emergent patterns from AI-generated code in staging—before they become production incidents.
Learn About Dstl8 Back
Backpress@controltheory.com


