“We didn’t realize there was a problem… until the Datadog bill landed.”
If that sounds familiar, you’re not alone. At some point, nearly every engineering or platform team working with Datadog hits this moment: a sky-high Datadog bill that doesn’t match the value you’re seeing. These Datadog pricing issues often stem from unchecked telemetry practices.
And the worst part? It’s often nobody’s fault.
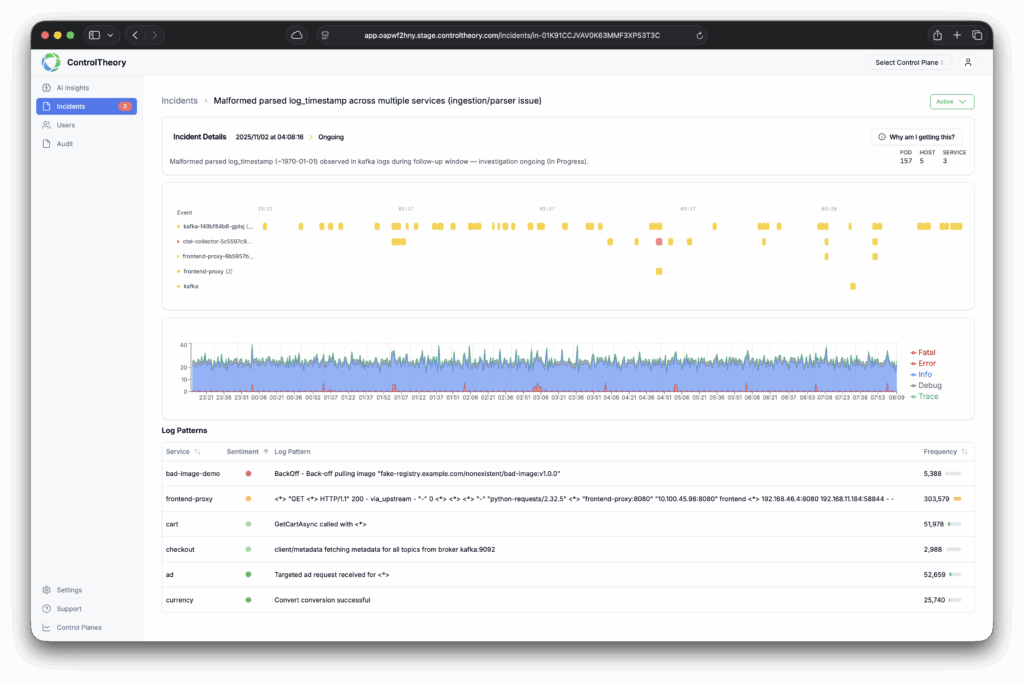
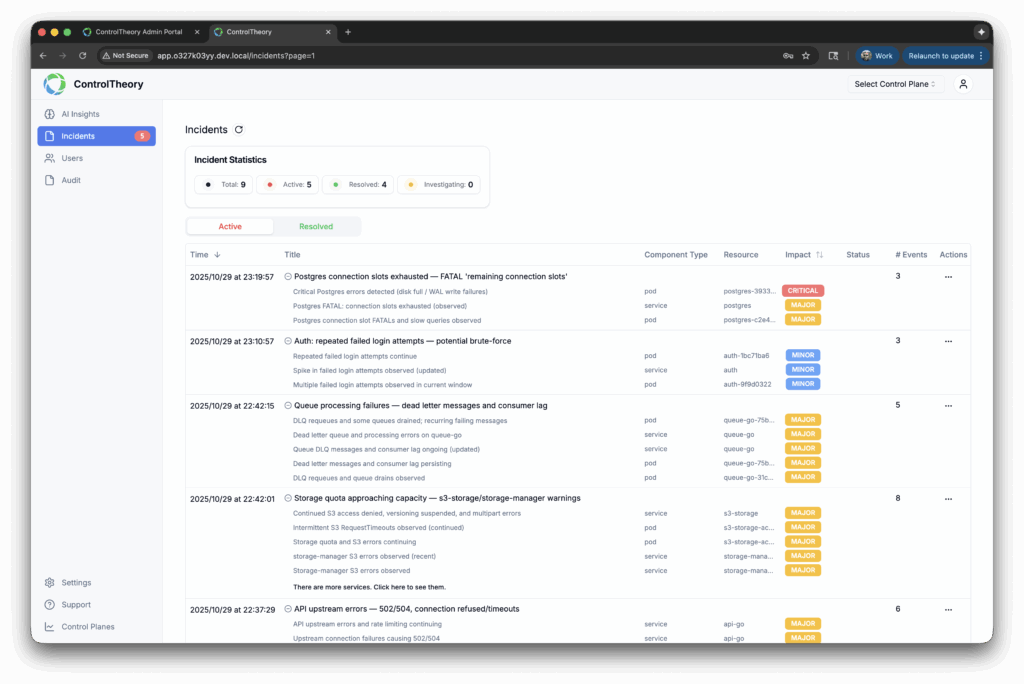
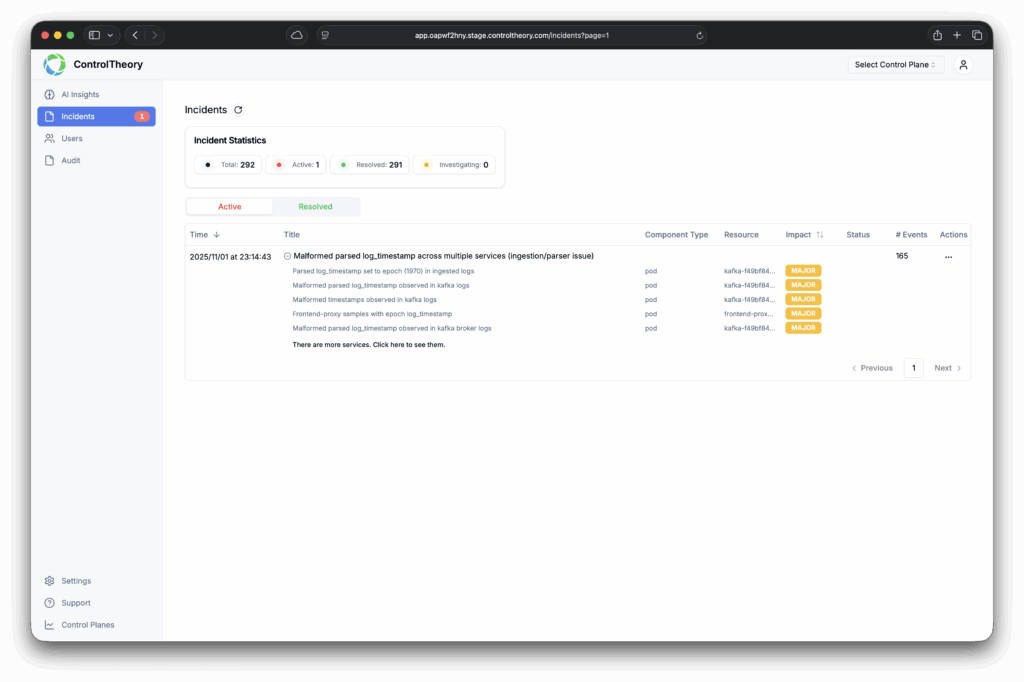
You’re collecting Datadog logs, custom metrics, and traces because it’s the right thing to do. You need visibility, accountability, and the ability to troubleshoot fast. But under the hood, there’s a silent force driving up costs, slowing down dashboards, and making your observability stack harder to manage: Datadog cardinality.
In simple terms, metric cardinality (or Datadog cardinality) refers to the number of unique tag combinations your telemetry generates. And when you tag everything — env, region, user_id, container_id, and more — your seemingly simple metric like api.request.count can explode into millions of unique time series.
Multiply Datadog cardinality across Datadog metrics, logs, and Datadog APM traces, and you’ve got:
Millions of indexed log lines you’ll never query
Tracing pipelines full of low-value spans
Engineers turning off observability just to reduce Datadog cost
And the numbers back it up:
One major cloud platform team saw 80% of its telemetry spend driven by just 7% of data — most of which was never queried.
Datadog billing is driven by Datadog custom metrics and indexed logs — meaning cardinality directly impacts your invoice, even if the data isn’t useful.
Tracing at scale can result in millions of spans per minute, especially with verbose instrumentation and no intelligent sampling or control layer in place.Millions of indexed log lines you’ll never query.
This isn’t just a financial issue. It’s an operational one. Observability becomes noisy, slow, and unreliable. Teams lose trust. Engineers fly blind. And eventually, someone asks, “Should we just move off Datadog?”
But here’s the thing: Datadog pricing isn’t the problem. Mismanaged telemetry is.
So how do make Datadog work better and not just more expensive? Check out four keys ways to help you take back control of your observability stack — without ripping out tools or losing visibility. Below, we walk through where things go wrong, why costs spiral, and how smart teams are reclaiming clarity, speed, and confidence — all while cutting waste and cost.
Learn how Datadog cardinality and tag explosion breaks your Datadog cost model and clogs your dashboards — and what you can do to reduce it without sacrificing data quality. Learn More…
Logs are crucial — but expensive. We’ll show you how to reduce Datadog log duplication, route intelligently, and keep high-value logs where they belong. Learn More…
Discover how tail-based sampling, OpenTelemetry, and intelligent pipelines can give you full context traces and help you manage Datadog pricing. Learn More…
AI-powered SRE tools are only as good as the telemetry they ingest. We’ll break down how to give your automation clean, complete, and actionable data. Learn More…