As more teams adopt OpenTelemetry (OTel) to unify observability signals across metrics, logs, and traces, one of the most critical decisions is how to deploy the OpenTelemetry Collector. The right deployment pattern can dramatically affect scalability, latency, resilience, and manageability — especially as your telemetry footprint grows.
In this guide, we explore common OpenTelemetry Collector deployment models and the trade-offs that architects and SREs should consider in the planning phase.
Agent vs Gateway: The Foundational Decision
The most fundamental choice is whether to run the OTel Collector as an agent, a gateway, or a combination of both.
- Agent model: Collectors run as sidecars or daemonsets near your application workloads. Ideal for capturing host-level telemetry and reducing dependency on network availability.
- Gateway model: Centralized collectors aggregate and process telemetry before exporting it. Good for central processing, batching, enrichment, and applying policies like tail-based sampling.
Best practice: Use agents to collect local telemetry and send it to a gateway for centralized processing and routing.
Federated Collectors: Regional Scalability and Isolation
Federated deployments introduce edge or regional OTel collectors that forward data to upstream gateways. This approach improves:
- Scalability: Horizontal scaling across regions or zones.
- Latency: Regional collectors reduce round-trip time to gateways.
- Blast radius control: Issues in one region don’t affect others.
This is especially useful in multi-cluster or multi-region Kubernetes environments.
Shared vs Dedicated Collectors: Tenancy Trade-offs
In shared environments (e.g., centralized observability teams), you may operate multi-tenant collectors that handle traffic from many services or teams.
- Shared collectors are easier to manage but increase risk if misconfigured (e.g., a noisy tenant can cause overload).
- Dedicated collectors provide stronger isolation and performance predictability, but require more resources and coordination.
One hybrid pattern: run shared collectors for legacy or vendor-specific traffic (e.g., Datadog receivers and exporters) during migration, while using dedicated collectors for modern OTel-native telemetry. Another pattern we’re seeing is assignment of a dedicated collector to a product team (under their control) that understands the specific needs of their application or component, to then be fed into a centralized collector.
Protecting Your Observability Backends
OpenTelemetry Collectors act as a buffer and policy enforcement layer, helping protect observability platforms from:
- High-cardinality metric floods
- Trace spikes
- Log ingestion storms
With the right configuration, they can batch, throttle, and drop low-value telemetry before it reaches costly backends like Datadog or New Relic — reducing risk and spend.
Load-Balanced Gateway Collectors
For higher availability and throughput, run multiple gateway collectors behind a load balancer. This pattern:
- Enables horizontal scaling
- Reduces risk of single-point failure
- Improves throughput and resilience
Ensure collectors are stateless where possible, or use consistent hashing or sticky sessions when stateful processors (e.g., tail-based sampling) are involved.
Kubernetes Deployment Options
In Kubernetes, the OTel Collector can be deployed in several ways:
- DaemonSet: Ideal for agent mode. Collects node-local logs/metrics.
- Deployment: Used for gateway collectors with horizontal scaling.
- Sidecar: Per-pod agent model, gives high-fidelity context, and applicable to serverless deployments like AWS Fargate or GCP Cloud Run
- StatefulSet: For collectors with stateful processors (e.g., tail-sampling, spanmetrics).
Use readiness probes, resource limits, and anti-affinity rules to ensure stability and isolation.
Self-Monitoring and Telemetry of OTel Collectors
OpenTelemetry Collectors can monitor themselves by exporting internal metrics like:
- Pipeline throughput and drop counts
- Exporter latency and failure rates
- Processor queue lengths
Configure a metrics receiver and exporter (e.g., Prometheus) to scrape and visualize these stats. It’s essential for debugging, tuning, and autoscaling.
Security and Authentication
Security considerations include:
- TLS encryption for all ingress and egress traffic
- Authentication extensions (e.g., basic auth, mTLS, OIDC)
- Rate-limiting and circuit breaking to prevent misuse
- Tenant separation using headers or attributes
For multi-tenant collectors, enforce strict attribute-based routing and resource-level quotas.
Advanced Patterns: Layering, Sampling, and Spanmetrics
For high-scale deployments:
- Use layered collectors (e.g., edge agent → load balancer → tail-sampling gateway).
- Apply tail-based sampling in centralized collectors to cut APM costs.
- Leverage the spanmetrics connector to convert spans into (RED) metrics for SLO tracking.
- Use batch and memory_limiter processors to reduce backpressure and crashes.
Some components (like the tail_sampling processor and spanmetrics connector) are stateful and may require more memory and coordination across replicas.
Final Thoughts
There’s no one-size-fits-all OpenTelemetry Collector deployment. Your pattern should reflect:
- Telemetry volume and cardinality
- Latency and processing needs
- Organizational boundaries
- Platform resiliency and cost control goals
By thoughtfully designing your deployment architecture, you can ensure observability doesn’t come at the cost of reliability, performance, or spiraling costs.
Need help with your OpenTelemetry Collector rollout?
ControlTheory helps teams design scalable, cost-effective observability controls. Get in touch or check out our guide to reducing observability bloat.
Table of Contents
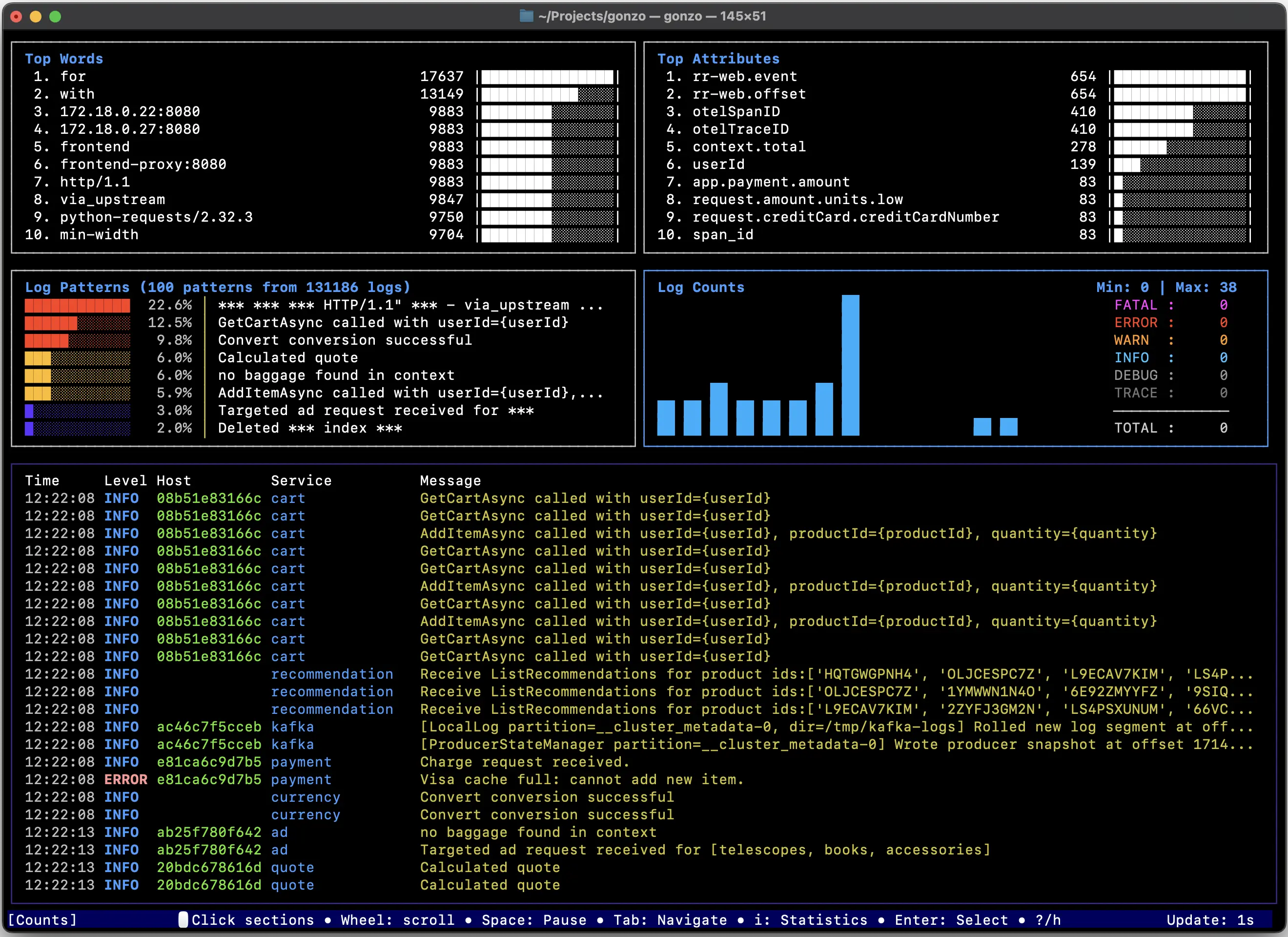
Logs. Understood. Instantly.
Analyze logs directly in your terminal with real-time insights and AI-powered pattern detection—no dashboards, no friction.
Get Gonzo Back
Backpress@controltheory.com